

I’ve been using Goodreads consistently for the last 8 years to line up future reads and rate books I’ve read. Recently, I exported these 8 years’ worth of data and analysed it to see how my reading behaviour has changed.
As an extension to this, I’m going to see if it’s possible to predict how much I will like/dislike a book.
The dataset
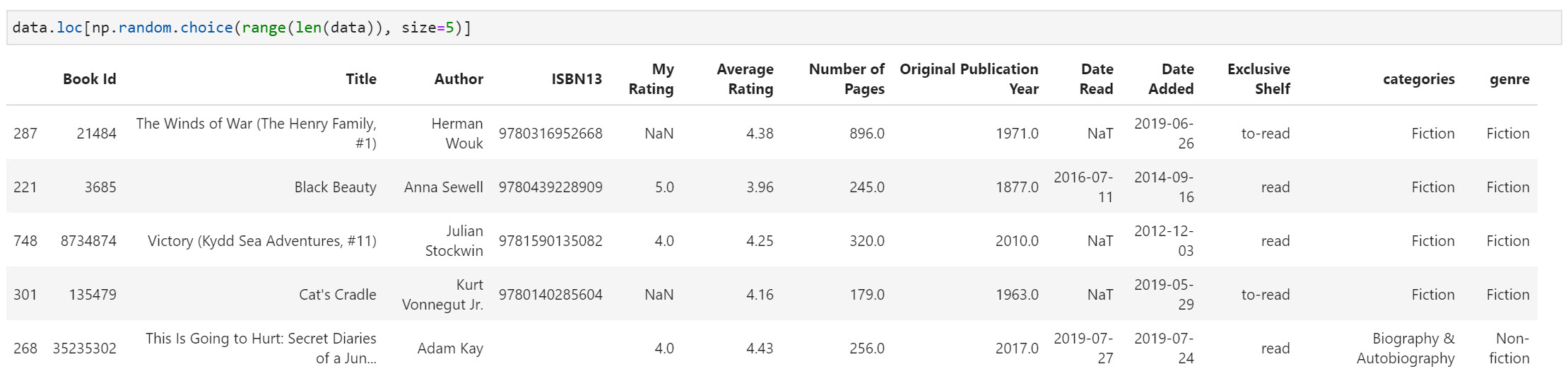
The dataset contains quite a few features:
- Book details - Title, author, ISBN, original publication year
- Goodreads platform data - Rating given by Goodreads members
- Personal reading data - Rating given by user, date read, date added to a shelf, shelf the book is currently on i.e. to-read, read, currently-reading
Some top level numbers
- I’ve rated 615 books
- My average rating is 4.29 out of 5
- 75% of the books read are fiction and the rest are simply labelled non-fiction
Pre-processing
To keep things as simple as possible I’ll only do the following pre-processing steps to prepare the data.
- Extract any series numbers that exist in the ‘Title’ column - it might be a sign I like a book if I’m 11 books into the series.
- Removal of the ‘Book Id’, ‘Title’, ‘Author’ and ‘ISBN13’ columns
- Convert the datetime columns (‘Date Read’ and ‘Date Added’) to be relative to days before now
- Impute missing values with the mean
- Hot encode the ‘genre’ (Fiction vs non-fiction) column
The Preprocessed Data

Modelling the data
Since there are only five possible ratings I can give, I’ve framed this question as a Classification problem, hoping to predict which rating I am likely to give. I’m going to throw a few classifiers at the data to see what sort of accuracy they come back with.
Here we’ll use Logistic Regression, Decision Trees and KNN alongside a Voting Classifier ensemble method to round it off.
Findings
We score the models based on their accuracy which I judge to be a suitable metric for this classification problem.
Logistic Regression score: 0.45
Decision Tree score: 0.44
K Nearest Neighbors score: 0.39
Voting Classifier score: 0.42
Each of the models give a score between 0.39-0.45. With 5 possible labels and bearing in mind ~85% of the time I give either a 4 or 5, this is not a great accuracy.
In fact, this score proves no better than just randomly choosing a rating of either 4 or 5 each time.
from sklearn.metrics import accuracy_score
random_prediction = np.random.choice([4, 5], len(read))
accuracy_score(y, random_prediction)
# 0.43
Conclusion
Whilst it’s always fun to create a model with a high accuracy, in the end I’m happy that I’m not so predictable in how much I’m going to enjoy a book. Maybe if the model was accurate, I could have picked future books by plugging them into the model to see what rating I was likely to give, instead I’ll go back to the trusty method of judging a book by its cover.
With the world of books being as broad as it is, the data I’m plugging into the models is hardly granular. We’re generalising whole years and genres and it is not surprising that the models struggle to predict which rating I’ll give. A better method for predicting how much I’d like a book would be to use a dataset containing the ratings of thousands of users rather than just myself.
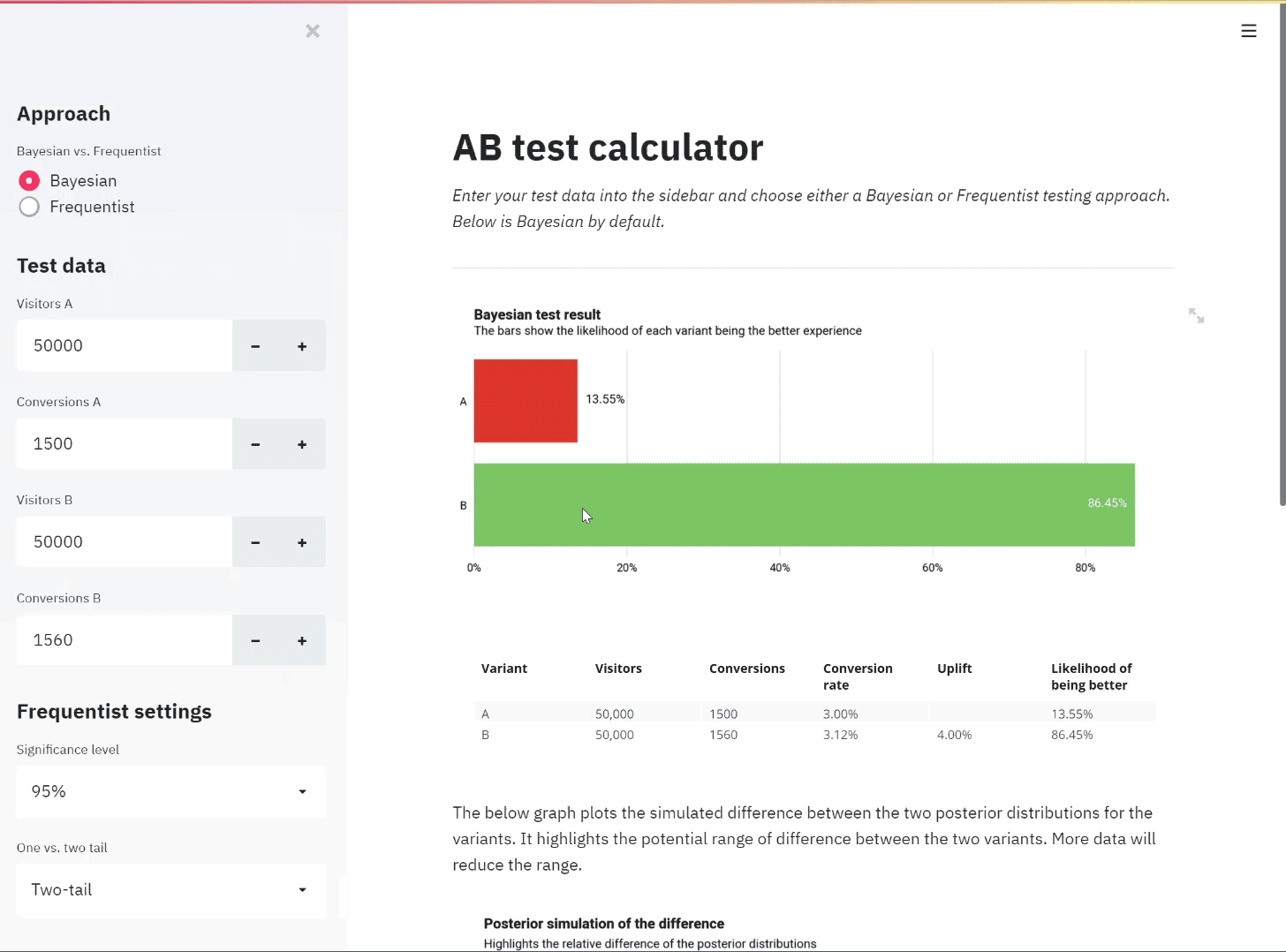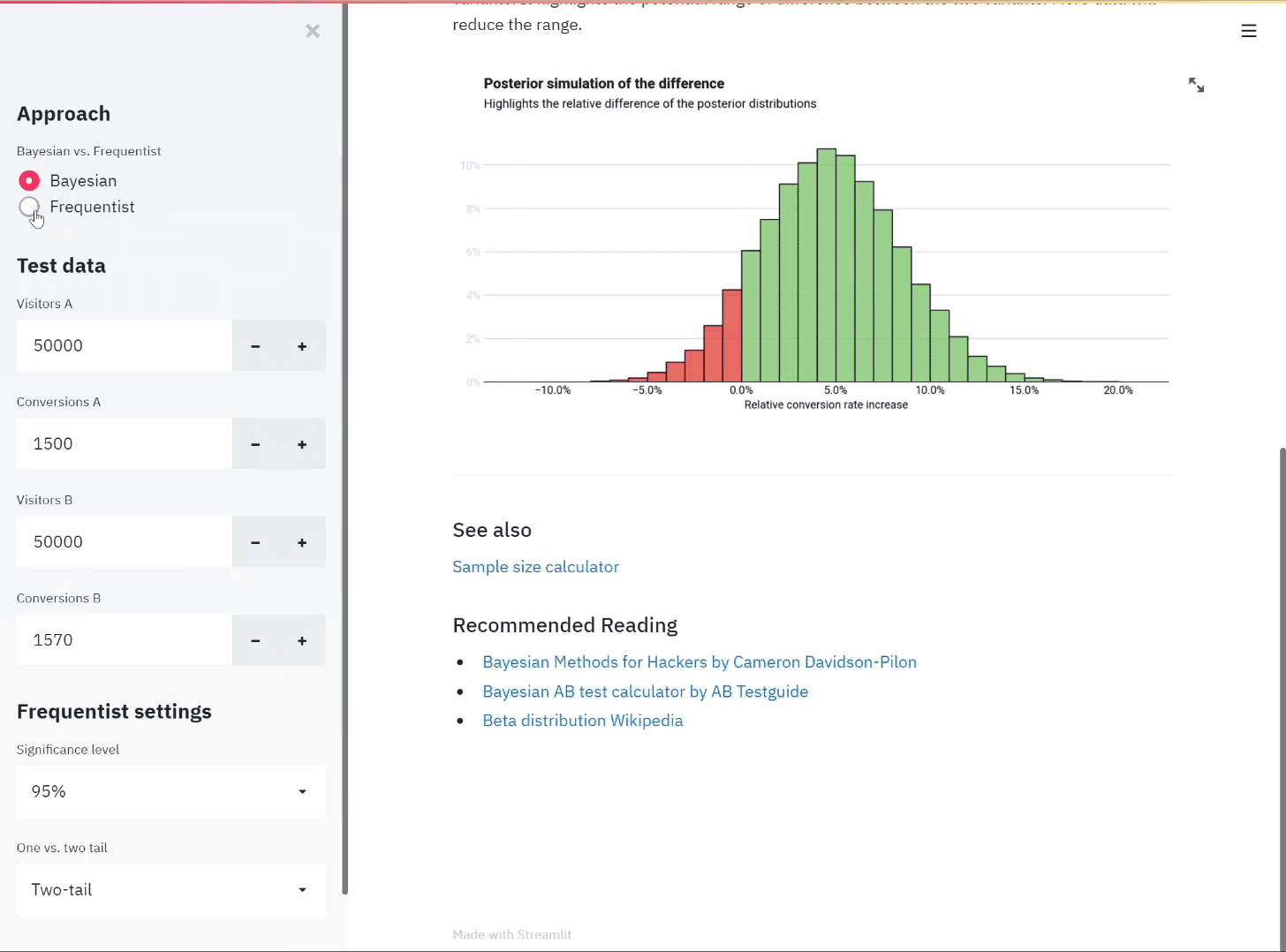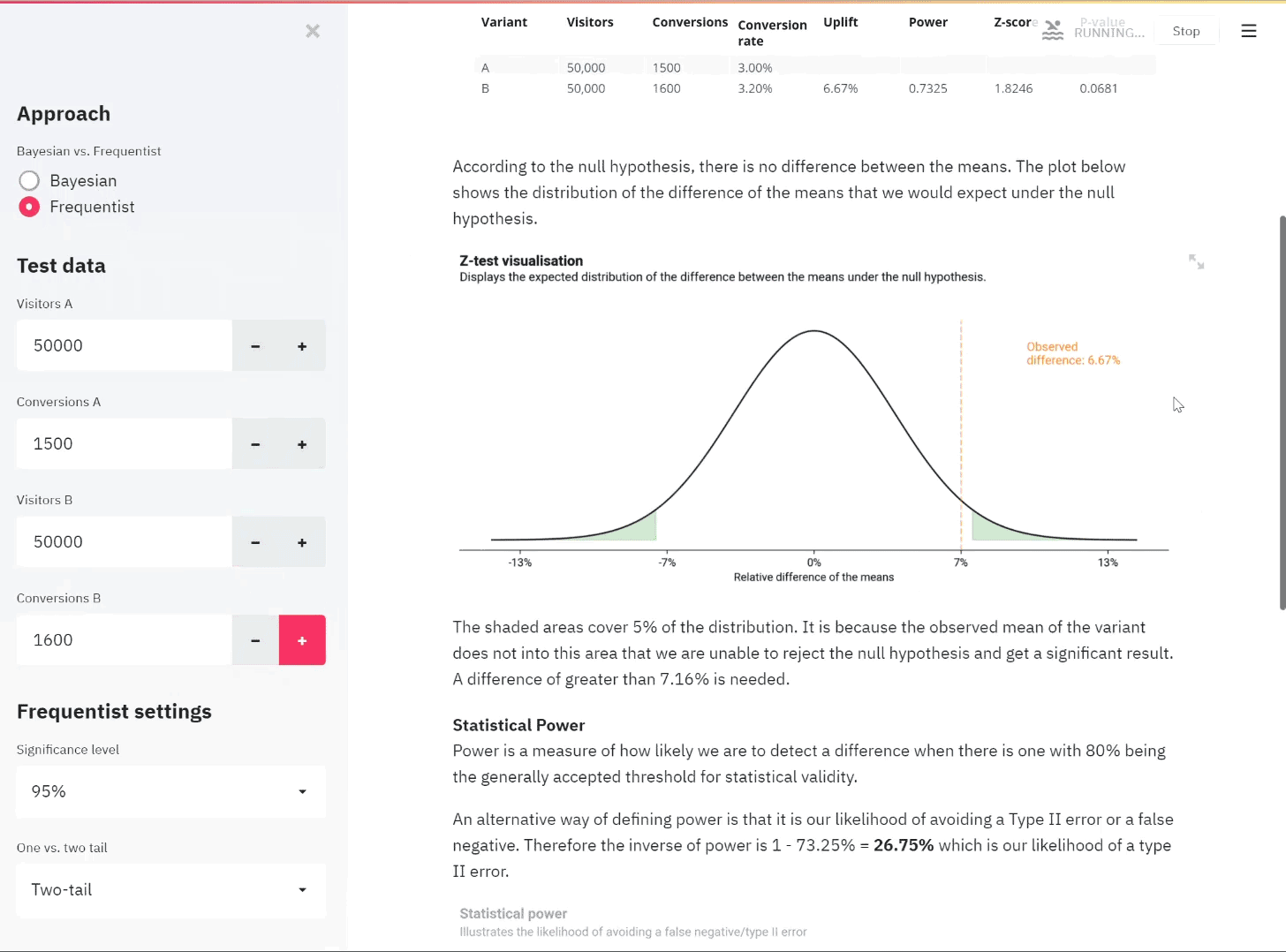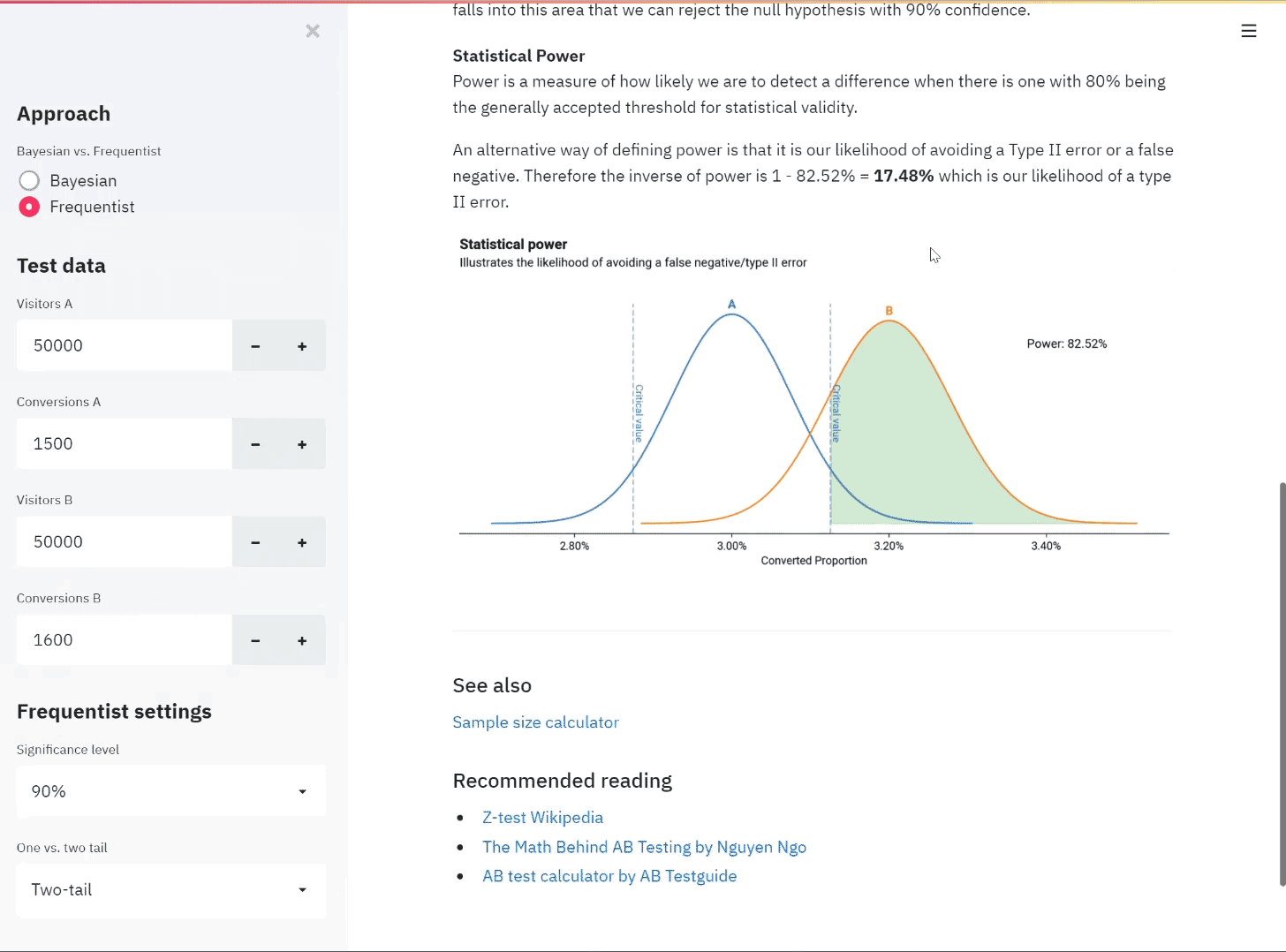
Creating an AB test calculator with both Frequentist and Bayesian approaches
What price should you charge for your Airbnb?

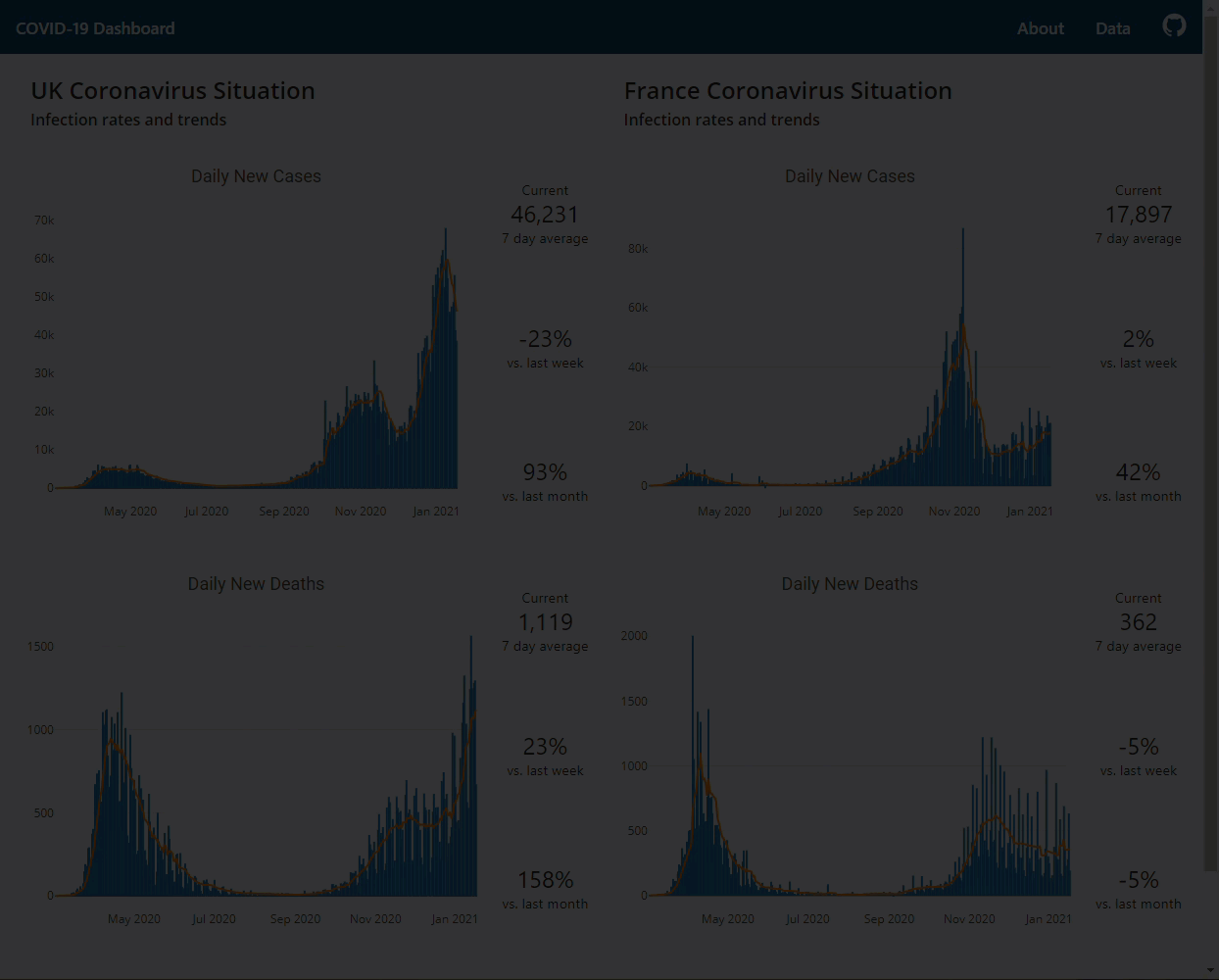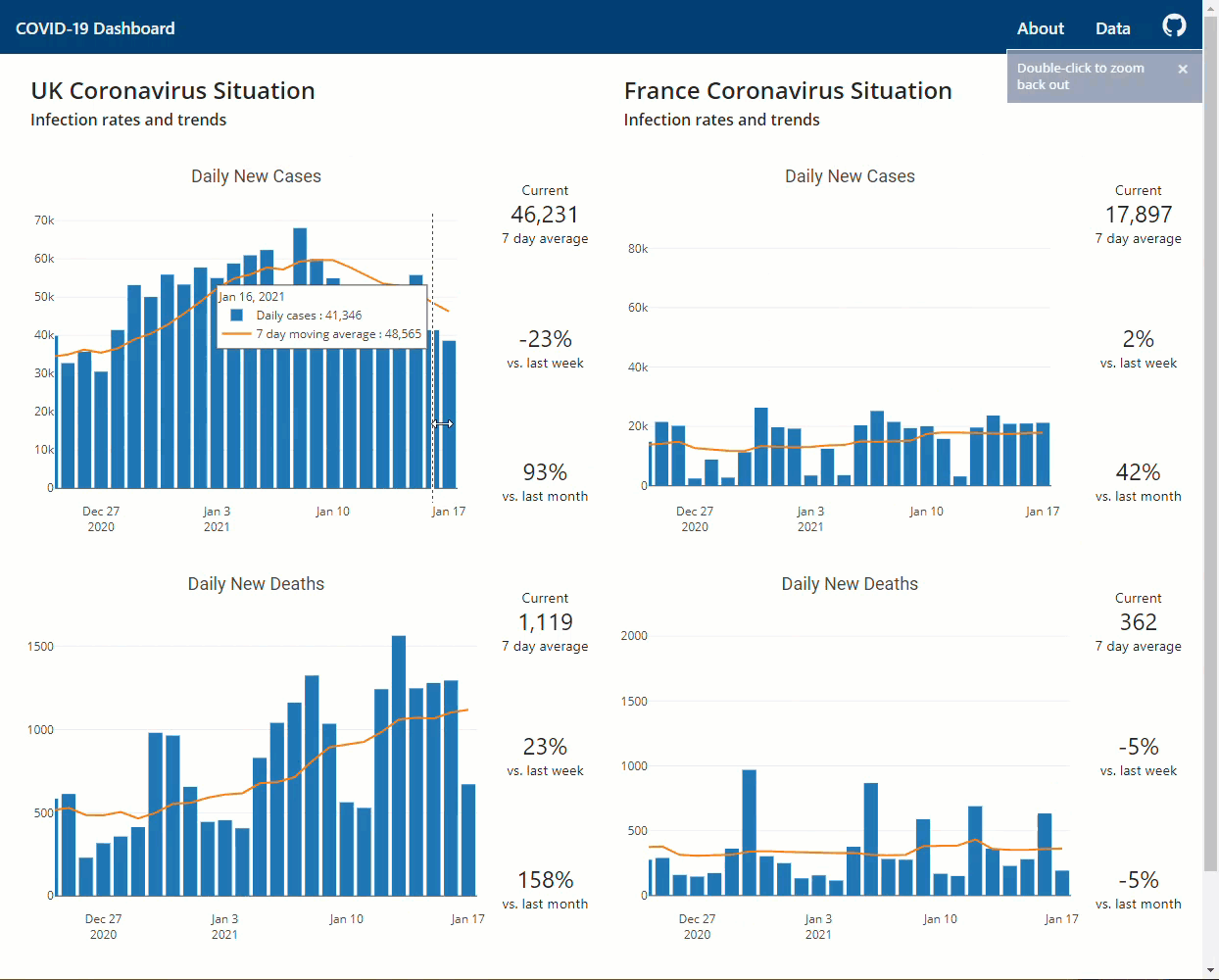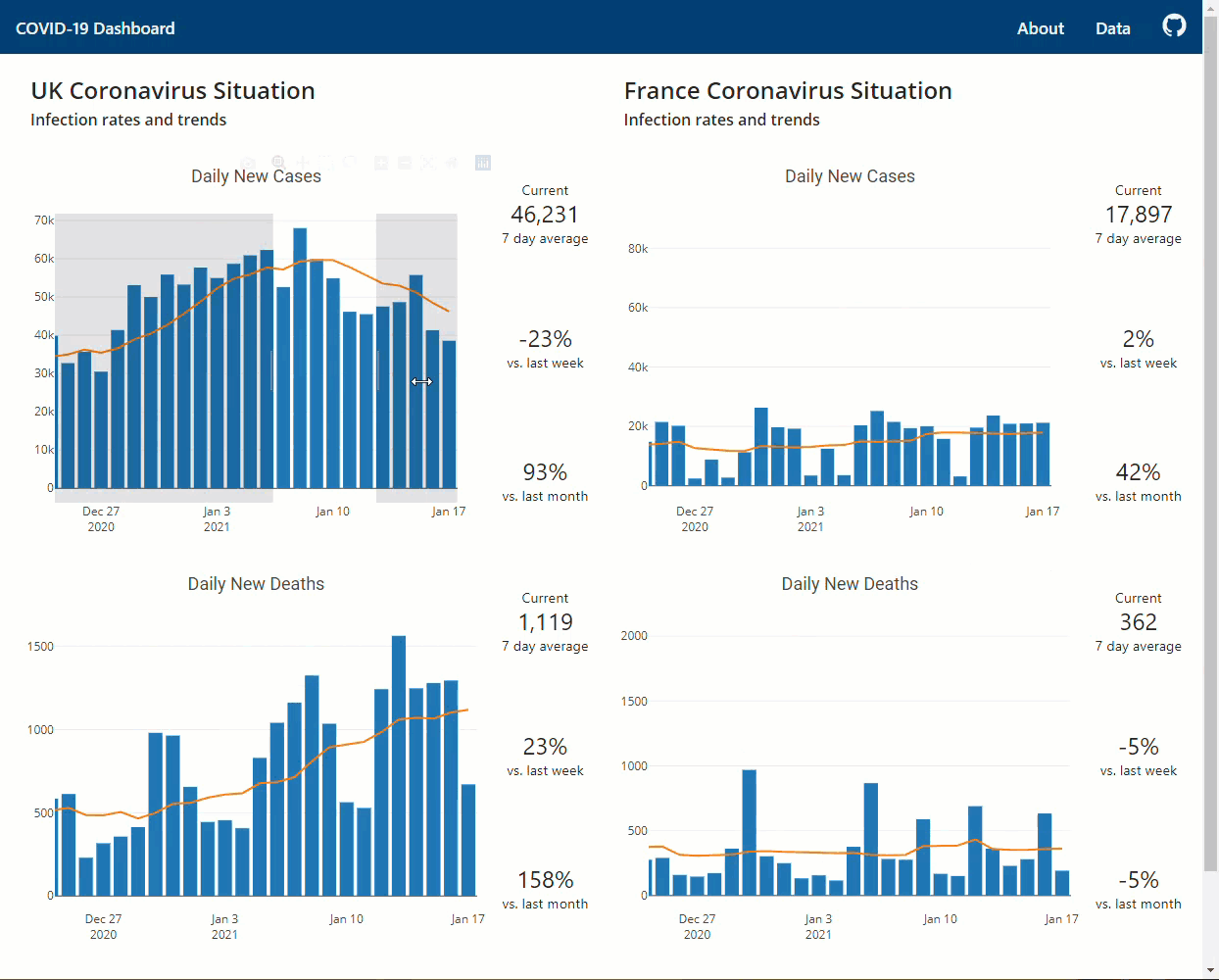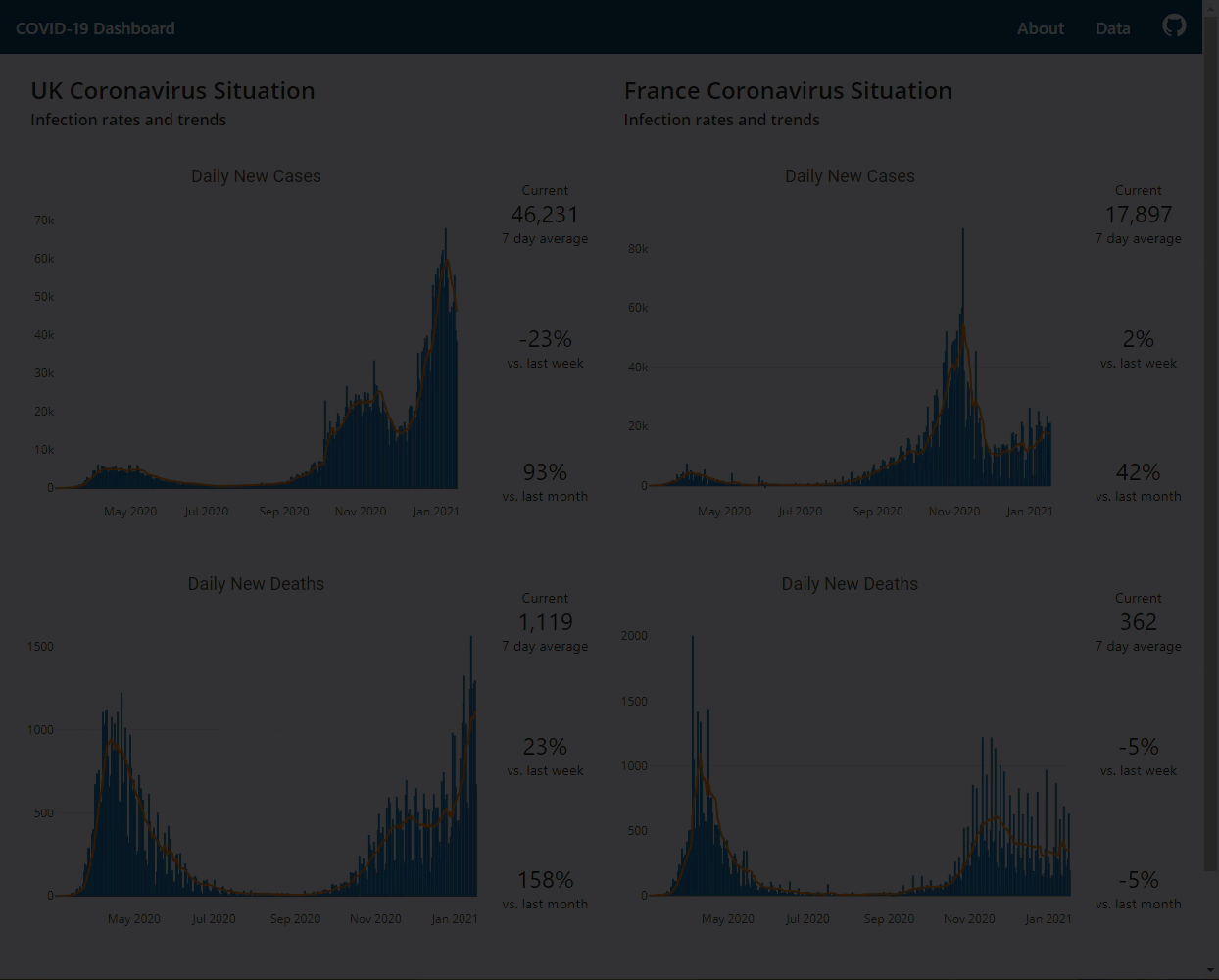

{kind=link}